








Hét flexibele marketing automation platform
laagdrempelig instappen, geavanceerde mogelijkheden - jij bepaalt

Ontdek de mogelijkheden

Meer controle voor technische teams
Of je nu op zoek bent naar soepele datakoppelingen of volledige controle over je e-mailomgeving, Copernica past perfect in jouw tech stack.

Ondersteunt moderne marketingteams
Breng de juiste boodschap via het juiste kanaal op het juiste moment, voor marketing die persoonlijker en effectiever is. Verbind je met je doelgroep op een manier die echt betekenisvol is.

Perfect voor marketingbureaus
Als marketingbureau is jouw doel klanten te laten groeien zonder gedoe of concurrentie. Gebruik een flexibel platform om meerdere klanten te beheren en behoud controle wanneer nodig.
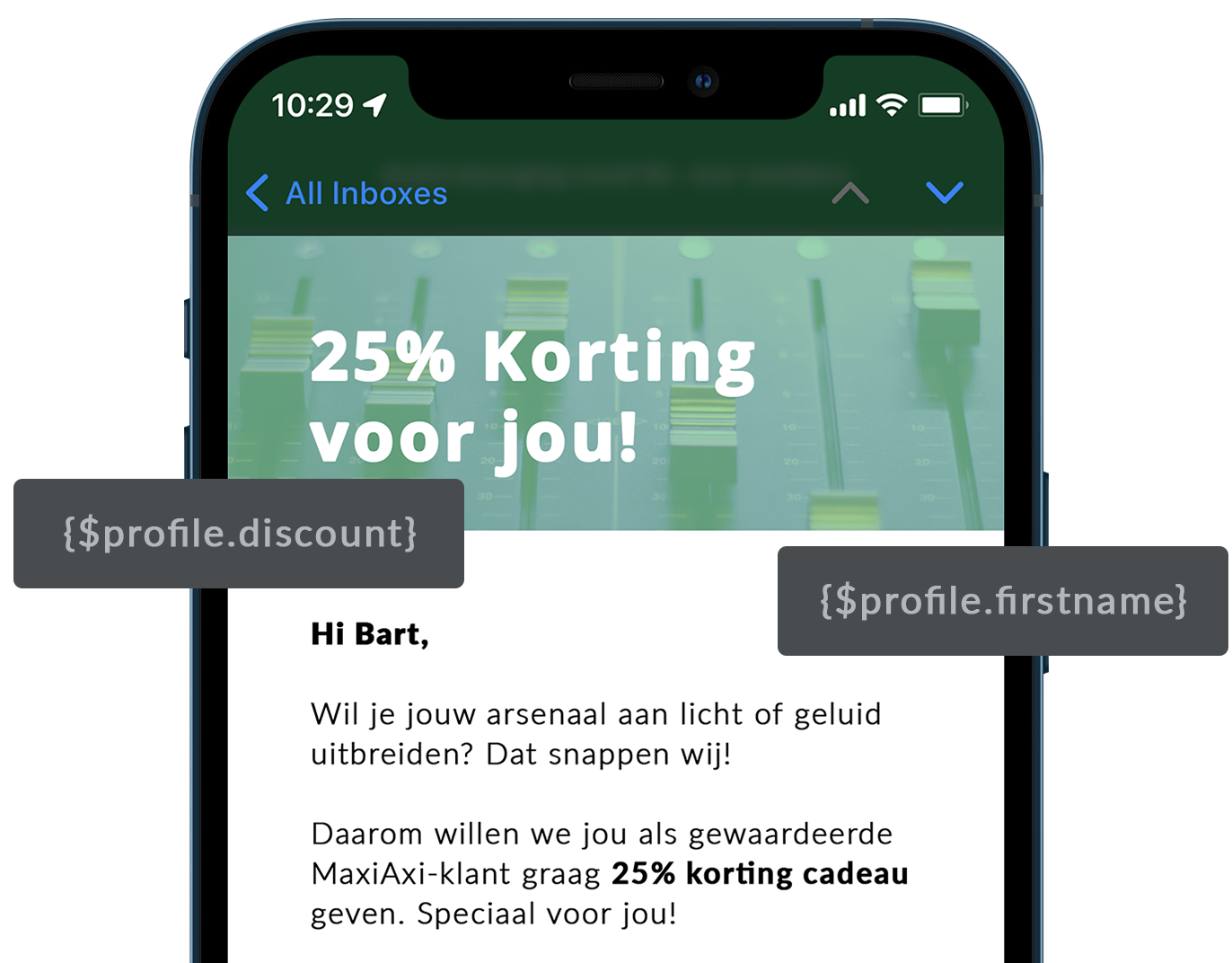
MaxiAxi boekt 705% groei in e-mailmarketing
MaxiAxi heeft een groei van 705% omzet uit hun e-mailkanaal weten te realiseren in slechts vier jaar tijd. Dit hebben zij gedaan door een goede koppeling neer te zetten en vervolgens gefaseerd automatische campagnes op te zetten in de customer journey.
Van ‘one sizes fits all’ naar hyperpersonalisatie in e-mail
Het verzamelen van data is de laatste jaren steeds belangrijker geworden en consumenten willen producten zien die voor hen relevant zijn. Tegelijkertijd hechten consumenten steeds meer waarde aan privacy, wat leidt tot strengere regels rondom dataverzameling.

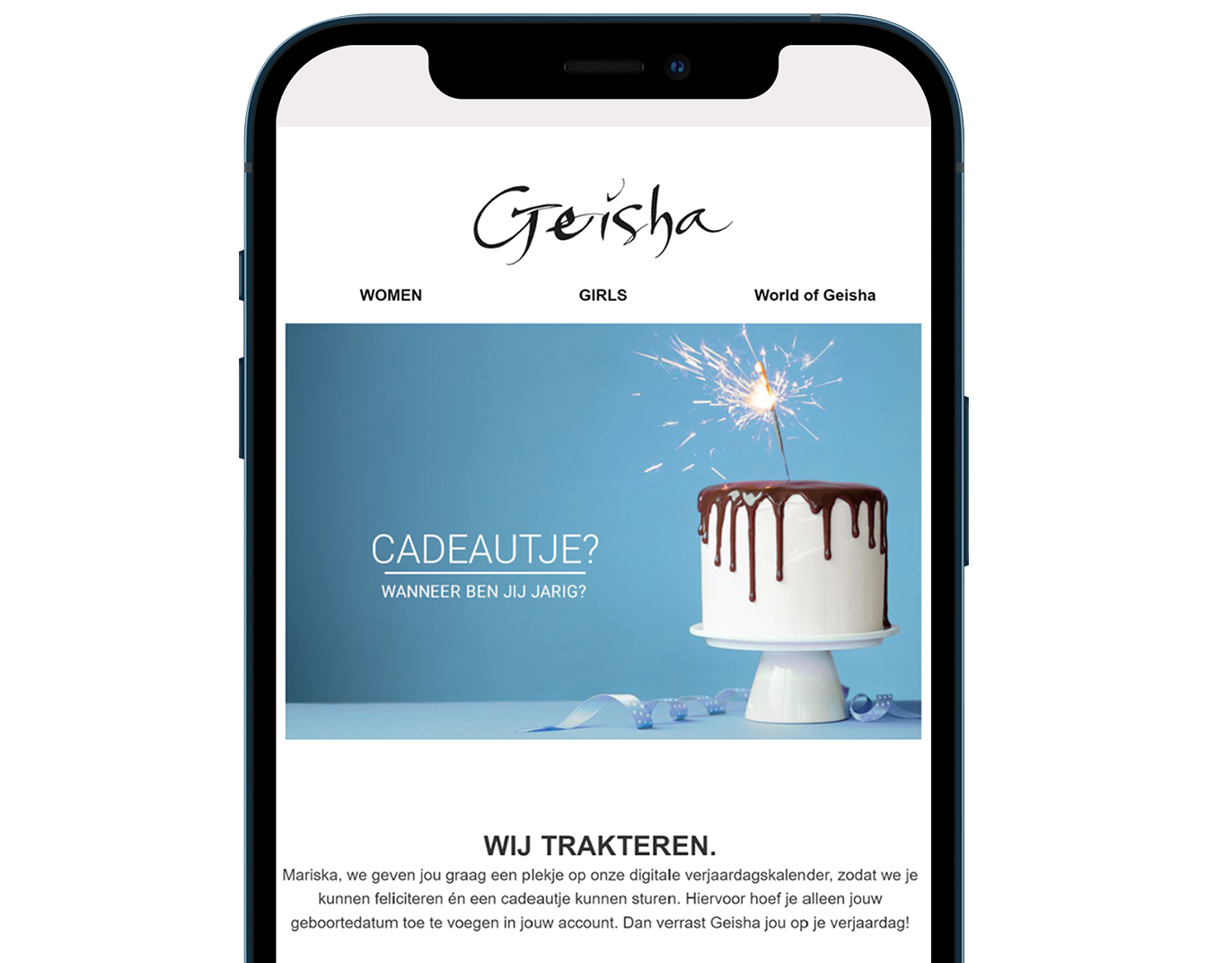
De lessen van Geisha Fashion bij het opzetten van e-mailmarketing
Geisha Fashion heeft sinds het oprichten van hun B2C-webshop drie jaar geleden, een e-maildatabase van 40.000 profielen opgebouwd. Door een sterk loyaliteitsprogramma op te zetten, verschillende campagnes uit te proberen en flexibel te blijven in het bijschaven van de strategie, komt inmiddels 15,7% van de omzet uit online aankopen.
10x meer omzet uit e-mail
De Telegraaf Webshop vertienvoudigde de omzet uit e-mailmarketing in de afgelopen twee jaar door de dagelijkse nieuwsbrieven te optimaliseren. Het aandeel van de e-mailautomations ten opzichte van handmatig nieuwsbrieven opmaken is inmiddels gegroeid van 3,6% in 2021 naar 40% in 2024.
Onze producten
Copernica biedt drie krachtige oplossingen voor professionele (e-mail)communicatie.
Vergelijk onze producten
Uitgebreid e-mail marketing platform
E-mailmarketingsoftware ontworpen om bedrijven en marketeers effectief te helpen bij het beheren en optimaliseren van marketingcampagnes. Met de features van de Marketing Suite stel je geautomatiseerde campagnes in en haal je meer uit elke klantinteractie.

Flexibele & snelle MTA
MailerQ is een on-premise Linux-gebaseerde Mail Transfer Agent (MTA) voor het bezorgen van grote hoeveelheden e-mail per dag. Met de real-time beheerconsole en unieke functionaliteiten kan je de afzenderreputatie en afleverpercentages behouden en verbeteren.

Cloud based-e-mail-service
SMTPeter is een cloudservice om uitgaande e-mails te optimaliseren met authenticatie, statistieken en verbeterde afleverbaarheid. Verbind met SMTPeter via de krachtige REST API om je e-mails veilig af te leveren bij de ontvangers in hun inbox.
Meer dan 300 partners bieden ondersteuning
Klaar om je te helpen met campagnemanagement, professionele html-templates en meer.
Leer meer



